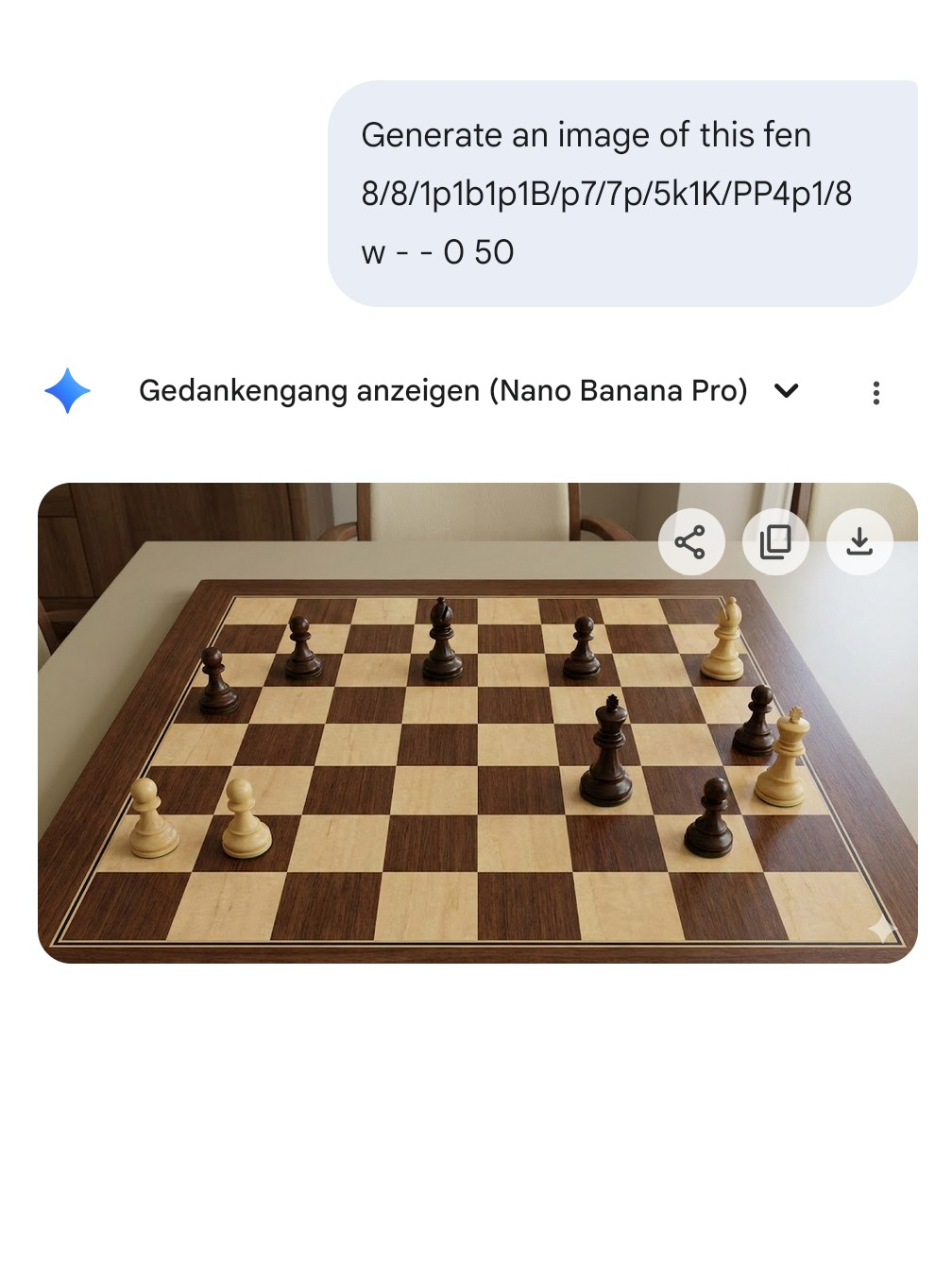
One other test you could add is generating a chessboard from a FEN. I was surprised to see NBP able to do that (however, it seems to only work with fewer pieces, after a certain amount it makes mistakes or even generates a completely wrong image) https://files.catbox.moe/uudsyt.png
Since they are set open, I assume they are actually using them as if they were en-dashes and not em-dashes, which the more common style would be to set closed, but I’m guessing, in either case, the reason is “because you can type it on a normal keyboard without any special modification, Compose-key solution, or other processing, and the author doesn't care much about typography”.
EDIT: Though these the days it could also be an attempt at highly-visible “AI didn't write this” virtue signaling, too.
Yes; because - is on the keyboard and — isn't. (Don't tell me how to type —, I know how, but despite that it is the reason, which is what the parent comment asks about.)
It's just that I have the feeling that people avoid using the actual em-dash in fear of being accused that the text is ai generated. (Which isnt a valid indicator anyway) Maybe its just my perception that i notice this more since LLMs became popular.
my original word processor corrected “—-“ to an em-dash, which i would get rid of because it didnt render correctly somewhere in translation between plaintext- markdown- html (sort of how it butchered “- -“ just now on HN.)
but what youd see in your browser was “square blocks”
so i just ran output through some strings/awk /sed (server side) to clean up certain characters, that i now know specifying “ utf-8 “ encoding fixes altogether.
TLDR: the “problem” was “lets use wordpress as a CMS and composer, but spit it out in the same format as its predecessor software and keep generating static content that uses the design we already have”
em-dashes needed to be double dashes due to a longstanding oversight.
The Original Sin was Newsmaker, which had a proprietary format that didnt work in anything else
and needed some perl magic to spit out plaintext.
I don’t work in that environment or even that industry anymore but took the hacky methodology my then-boss and I came up with together.
SO,
1) i still have a script that gets rid of them when publishing, even though its no longer necessary. and its been doing THAT longer than “LLMs” were mainstream.
and 2) now that people ask “did AI write this?” i still continue with a long standing habit of getting rid of them when manually composing something.
Funny story though after twenty years of just adding more and more post processing kludge. I finally screamed AAAAAAAAHAHHHH WHY DOES THIS PAGE STILL HAVE SQUARE BLOCKS ALL OVER IT at “Grok.”
All that kludge and post processing solved by adding utf-8 encoding in the <head>,
which an “Ai” helpfully pointed out in about 0.0006s.
That was about two weeks ago. Not sure when I’ll finally just let my phone or computer insert one for me. Probably never. But thats it. I don’t hate the em-dash. I hate square blocks!
Absolutely nothing against AI. I had a good LONG recovery period where I could not sit there and read 40-100 page paper or a manual anymore, and i wasnt much better at composing my own thoughts. so I have a respect for its utility and I fully made use of that for a solid two years.
And it just fixed something that id overlooked because, well, im infrastructure. im not a good web designer.
This problem wouldn't exist if openai wouldn't store chatlogs (which of course they want to do, so that they can train on that data to improve the models). But calling nyt the bad guy here is simply wrong because it's not strictly necessary to store that data at all, and if you do, there will always be a risk of others getting access to it.
Maybe this is just some niche use-case, but I tested it with a 268x98 png screenshot, and it made the image bigger and worse: https://files.catbox.moe/7so3z6.png
You can schedule test calls and call in the scheduled time slot (US only)
Test calls confirm that your local 911 service can receive your 911 call and has the correct location information. Test calls can be scheduled by contacting your local 911 call center via its non-emergency phone number.
In your preferred search engine, search the key words “emergency communications center non-emergency number" and include the names of the city or town, state, and county or parish in your search. Test calls may need to be scheduled and are usually based on the workload experienced at the PSAP.
For more information, visit the National Association of State 911 Administrators site.
Please do not call 911 to obtain the non-emergency number.
That's not bypassing it, that's them finally engaging with the PoW challenge as intended, making crawling slower and more expensive, instead failing to crawl at all, which is more of a plus.
This however forces servers to increase the challenge difficulty, which increases the waiting time for the first-time access.
> After further investigation and communication. This is not a bug. The threat actor group in question installed headless chrome and simply computed the proof of work. I'm just going to submit a default rule that blocks huawei.
It doesn't work for headless chrome, sure. The thing is that often, for threats like this to work they need lots scale, and they need it cheaply because the actors are just throwing a wide net and hoping to catch it. Headless chrome doesn't scale cheaply so by forcing script kiddies to use it you're pricing them out of their own game. For now.
Doesn't have to be black or white. You can have a much easier challenge for regular visitors if you block the only (and giant) party that has implemented a solver so far. We can work on both fronts at once...
That counts as something that can solve it, yes. Apparently there's now exactly one party in the world that does that (among the annoying scrapers that this mechanism targets). So until there are more...
Why does that matter? The challenge needs to stay expensive enough to slow down bots, but legitimate users won't be solving anywhere near the same amount of challenges and the alternative is the site getting crawled to death, so they can wait once in a while.
Too bad the challenge's result is only a waste of electricity. Maybe they should do like some of those alt-coins and search for prime numbers or something similar instead.
Of course that doesn't directly help the site operator. Maybe it could actually do a bit of bitcoin mining for the site owner. Then that could pay for the cost of accessing the site.
this only holds through if the data to be accessed is less valuable than the computational cost. in this case, that is false and spending a few dollars to scrape data is more than worth.
reducing the problem to a cost issue is bound to be short sighted.
This is not about preventing crawling entirely, it's about finding a way to prevent crawlers from repeatedly everything way too frequently just because crawling is just very cheap. Of course it will always be worth it to crawl the Linux Kernel mailing list, but maybe with a high enough cost per crawl the crawlers will learn to be fine with only crawling it once per hour for example
my comment is not about preventing crawling, its stating that with how much revenue AI is bringing (real or not), the value of crawling repeatedly >>> the cost of running these flimsy coin mining algorithms.
At the very least captcha at least tries to make the human-ai distinction, but these algorithms are just purely on the side of making it "expensive". if its just a capital problem, then its not a problem for these big corpo who are the ones who are incentivized to do so in the first place!
even if human captcha solvers are involved, at the very least it provides the society with some jobs (useless as it may be), but these mining algorithms also do society no good, and wastes compute for nothing!
{kind=link}
{kind=link}