What a great idea. I believe in this a trillion percent, due to the personal experience of watching myself and a stronger developer tackle similar problems at the same time. I relied on my brain and the standard tools of my system. He of course did the same, but also made a custom visualizer for the core of the algorithm. Night and day improvement!
So I'm a believer in the principles. But I'm also curious about throwaway743950's question. What are the things in the Glamorous Toolkit that concretely make it better for this style of programming than traditional tools? You say "[it] just happens to be a nice system of tools that make it easy to make more little tools", but that's got to be downplaying it. Switching environments is an agonizingly costly thing to do. What rewards await those who make the jump? Rubies? Emeralds? Custom views-with-nested-sub-custom-views? Curious (but not yet won over) readers want to know.
The typical Markdown answer to needing indentation preserved is the "code fence" (triple backquotes ```), though I imagine the problem with that is that Obsidian by default stops dealing with Wikilinks inside fenced code. I don't know Obsidian that well, but maybe there's a way to use a code fence and have it support Wikilinks inside?
A different direction to explore might be to explore proportional font coding techniques that rely less on whitespace. Lisp can be a good language to play with those ideas given whitespace isn't syntactic. Though idiomatic Lisp has certainly relied on semantic whitespace in coding styles for a very long time.
> I imagine the problem with that is that Obsidian by default stops dealing with Wikilinks inside fenced code
Exactly. Interestingly enough autocomplete is still triggered by [[ inside of a code block which is kind of funny. So writing code blocks works fine, it's just that they won't display with links.
> A different direction to explore might be to explore proportional font coding techniques that rely less on whitespace.
I'm definitely open to proportional font coding techniques being interesting, but in this case with all leading indentation unusable I doubt they'd be enough to get a normal experience. Unless you only write assembly so you can stick to the left margin <taps forehead>.
> I hope the author continues down this path and writes more about the experience.
I appreciate it=) I definitely want to write some more stuff up, in particular how code organization changes when you can tag and add attributes to definitions.
Hazel and Unison are two of the big ones. I'm friends with some of the Unison folks so I'm biased, but I really like how few features there are in the language. In general I'm just a huge sucker for subtractive improvement: if you can have a small number of awesome things (eg abilities) instead of a bunch of special case things (exception handling, monad trickery, dependency injection machinery) sign me up.
I know less about Hazel, my understanding is that it's source-code-in-CRDTs, which is definitely structured source code though may not technically be in a database.
You may have encountered leo [ https://leo-editor.github.io/leo-editor/ ]. I use it to pull in or write code and break it up into comprehensible pieces. It works, but it feels overcomplex. I'm open to something simpler, and will give this a try.
I had't seen it! The "clones" feature is cool, it sounds like they're way ahead in figuring out how to use transclusions effectively when coding.
Previously I'd thought of using transclusions for things like long-lived documentation. Now reading about Leo it seems like they'd be just as useful for creating short-term views into one's code. Eg start a refactor PR by transcluding all the relevant definitions into a doc. Now you can start writing PR comments in that doc before you even begin coding, and when you do all the relevant code is right there.
> As a language-agnostic thing, I suppose you need to prevent the machinery from pulling in keywords and variable names accidentally (or the insides of strings or comments).
Exactly. But zacgarby's right that you would want some auto-linking, so this is where language-specific plugins come in.
The difference from today's world would be that those plugins would leave their results explicitly serialized in the source medium, so they wouldn't have to keep being reconstructed by every other tool.
> I like the idea (also a fan of Unison's approach to code-in-the-db), but I worry about the potential issues that come from effectively having a single global namespace. Could be that I just don't have the discipline for it, though.
I have lots of thoughts on this. I was initially disappointed that Unison kept a unique hierarchy to organize their code-- that seems so filesystem-ey and 1990s.
However, I'm now a convert. The result of combining a unique hierarchy with explicit links between nodes is a 'compound graph' (or a 'cluster graph', depending, getting the language from https://rtsys.informatik.uni-kiel.de/~biblio/downloads/these...). These are very respectable data structures! One thing they're good for is being able to always give a canonical title to a node, but varying what that title is depending on the situation.
I think that for serious work the linearizer would want to copy this strategy as well. Right now it's flat because that's all I need for my website, but if you were doing big projects in it you'd want to follow Unison and have a hierarchy. In the `HashMap` folder you'd display `HashMap.get` with a link alias that shows plain `get`, but if that function is being called from some other folder it would appear as the full `HashMap.get`.
You could still do all the other cool stuff like organize by tags and attributes using frontmatter, but for the particular purpose of display names having a global hierarchy is useful.
EDIT: What matters more than what the linearizer does is what Obsidian displays, so it's there that the "take relative hierarchical position into account when showing links" logic would have to occur. That could be a plugin or maybe Obsidian's relative link feature, I haven't used the latter.
> this is great! i’ve been thinking about exactly this (though styled after Logseq rather than Obsidian) but not gotten as far as implementing anything.
Thank you! I think [[links]] will work out of the box with Logseq since they're the same as Obsidian. Transclusions will be in the wrong format since Obsidian transclusions look like `![[this]]`, but it would be quick to modify the linearizer to handle them.
You may not want transclusions though since transcluding code into other code is... very weird. I'm curious what use cases people come up with for it though.
I love Smalltalk, and have done a reasonable amount of messing around with Cuis (which is awesome and everyone should try it).
However this gives you two things that Smalltalk doesn't:
1. It's language agnostic (boring I know)
2. It promotes keeping your code and written texts in the same system where they're both first class. That way they can link between each other, transclude each other, be published together, be organized the same way, etc. I really think this is the most interesting thing about the project, it really feels important to me.
Caveat: right now my written documents can link to/transclude code, but it doesn't work the other way yet. This is because the linearizer will see a link from code to documents as another definition and try to jam it in the source file. This would be an interesting use case for typed links, but Obsidian doesn't a have them AFAIK. Kind of cool since I haven't seen many other use cases for typed links in the wild.
EDIT: It occurs to me that I've never used a Smalltalk notetaking or word processing program. Are there any that are integrated with the System Browser, so that they can link to (or even better embed) code? If anyone has more info please let me know!
Lepiter is a Pharo-based notetaking app within the Glamorous Toolkit. I'm not sure it's mature enough to compete with Obsidian/etc., but it does allow linked and embedded code like you were thinking.
Of course! I should have just guessed they'd already have something like this.
We either need to port ALL of Glamorous Toolkit to mainstream langs or we need to convince all our employers to switch to Smalltalk. I am not certain which of those is possible or easier.
I'd say the porting is better. I've gone a ways into using GToolkit, and it has some very nice things. I especially like the infinite nesting of editors, which is like transclusion on steroids, and the driller. And it's already language agnostic and very extendable.
But when it comes to actually extending it, that's where the sharp edges start to cut. I was able to do a fairly quick, enhanced Python support extension, but one of the issues is getting proper class equivalence, and the back-and-forth passage of data is a major performance suck. Also things will grind to a halt if you push and try to process too much data at once on the Smalltalk side. Maybe having a fairly beefy machine will help with that though.
> Circuit switched analog POTS has been dead for a long time, but delays were limited to amplifier delays (almost nothing) and speed of light in wires or radio.
Two questions about this: it sounds like there are still a fair amount of landlines around if this article is accurate: https://www.cnn.com/2024/02/05/tech/landline-phone-service-p... Do you mean that people still have landlines, but they're no longer circuit switched analog? And would that only be for long distance, with local landline calls still using circuit switched analog, or would it be for both?
Also, as to your latter point about old school POTS having almost no delays other than speed of light: does that hold for long distance calls as well? I get the impression that there could be added latency for long distance POTS calls (but have had trouble finding sourced numbers on anything yet).
The central office switch that a landline is connected to is almost certainly doing analog/digital conversion. Digital switches were introduced in the 1970s and Analog exchanges were all but extinct by 2000 (according to [4], the last step by step exchange in Canada was replaced in 2002). If the call remains old school POTS, it will be essentially a T1/PRI call from that point on. Circuit switched digital calling was phased in over time, as CO switches were replaced. Chances are, a landline is actually handled by a remote terminal out in the field, and a/d converted there.
Long distance (to most destinations) calling probably switched to digital trunks faster than local calling, because long distance calling was already separate equipment from local calling, and replacing central office switches is a big process (including a pretty intense cutover [1]).
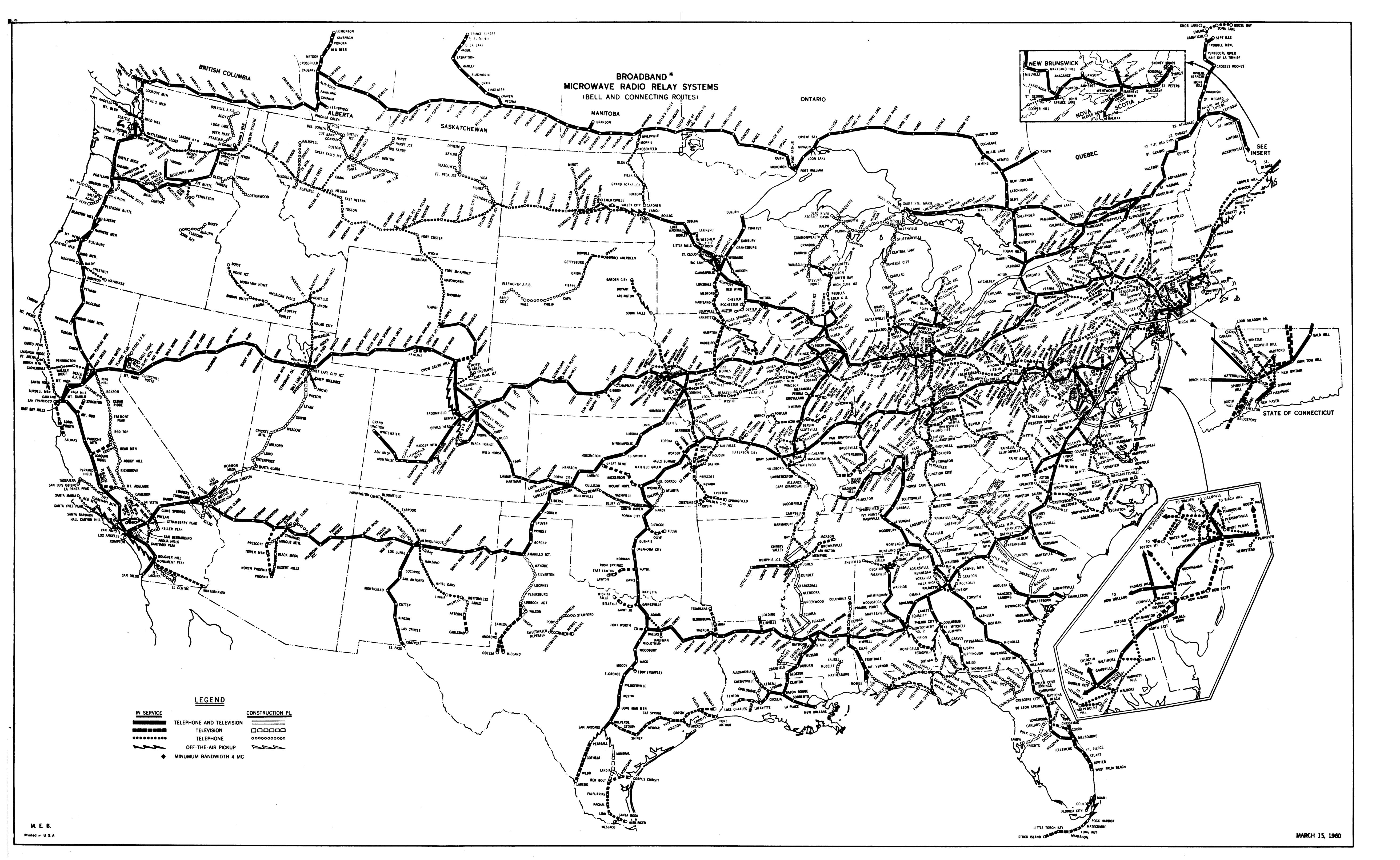
Long distance calling would have more equipment in the path than a local call, of course, and may not have had very optimal routing paths compared to today. I found a route map from the 1960 AT&T Long Lines network [2], and a fiber map with no provenance of 'today' [3] ... it's widely similar, but there's some routes that pop out at me as not being well connected in the 1960: Salt Lake City to Seattle; Amarillo, TX to Dallas, TX. On the other hand, Long Lines was radio, and radio is faster than fiber, so that makes up a little.
There may have also been more cases where routing was simplified to be more manageable at the expense of delay... AT&T wouldn't have run long distance trunks from everywhere to everywhere, you might need to do hierarchical routing --- if you're on the east coast, route to New York, and from there to the big city near your destination, and then to destination, etc. There's still some of that in internet routing, but it's a lot less. BGP and internal routing protocols make it a lot easier to manage more direct connections and let the software figure things out.
But there's no need to add a large buffer for voice data for POTS, and it was very expensive to do it, so it wasn't done. There is a need to do it for VoIP, and it's no longer expensive, so it is done.
I only read the first couple of paragraphs, but they imply that the architect (designer) and engineer (builder) were one and the same. Was that the case?
{kind=link}
So I'm a believer in the principles. But I'm also curious about throwaway743950's question. What are the things in the Glamorous Toolkit that concretely make it better for this style of programming than traditional tools? You say "[it] just happens to be a nice system of tools that make it easy to make more little tools", but that's got to be downplaying it. Switching environments is an agonizingly costly thing to do. What rewards await those who make the jump? Rubies? Emeralds? Custom views-with-nested-sub-custom-views? Curious (but not yet won over) readers want to know.