No, at FAANG I was coached to strictly evaluate based on individual merit, defined by some fixed rubric. We certainly would not penalize an applicant for attending a school with "too many" qualified graduates.
It's a standardized mean difference, which I believe can roughly be interpreted as: "treated groups had 0.67 stddev lower depression score than control groups."
That's a pretty substantial improvement - consider someone who's more depressed than 75% of the population becoming completely average. (Because the 75th percentile is about 0.67stddev above the median.)
You cannot say if this is a substantial change or not, because you need to know by how much the groups actually differ on average, i.e. you need the unstandardized effect size, expressed as a mean difference in the scale sum scores, or as an actual percentage of symptoms reduced, or etc. In general, there are monstrous issues with standardized mean differences, even setting aside the interpretability issues [1-3].
Good point. Would it be roughly accurate to say: "consider someone who's more depressed than 75% of the *study treated* population becoming completely average *among the study treated population*"?
Nope, you can't say how many people return to average from standardized effect sizes. I wish we had a standardized effect size that was more useful and actually meant something. Cohen actually proposed something called a U3 statistic that told us the percent overlap of two distributions, but that still doesn't tell us anything meaningful about practical significance.
You can't make decisions / determine clinical value from standardized effect sizes sadly, so when I see studies like this, my assumption is unfortunately that the researchers care only about publishing, and not about making their findings useful :(
> The last thing any big oil companies need is more crude supply into the market lowering the benchmark price even lower, especially particularly expensive (to extract) Venezuelan crude
Check Chevron's stock on Monday to see if you're right. My prediction: It will be significantly up, showing that the action benefited them.
Probably a bit of both. Berkshire's size means he was limited to the largest companies which are pretty well analysed.
During that period he did some different things which some of his personal money like buying stock in Dae Han Flour Mills, a Korean flour miller that was like 2 times earnings in 2003 but was probably too small a position to make sense for Berkshire. (https://www.netnethunter.com/warren-buffett-cheap-stock-pick...)
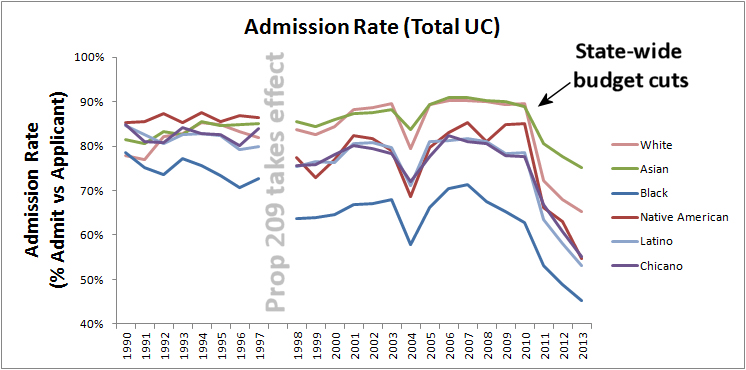
But you can look at trends in other comparable states compared to California both before and after CA outlawed AA at public California universities by referendum.
That includes government-run utilities, like LADWP, Silicon Valley Power, and SMUD, which have much lower rates than private utilities (And, no, the rate difference is not made up by taxpayer subsidies. They’re just run more efficiently).
Thanks for the context, I didn't realize the supervisor sits in the passenger seat in Austin. They do have a kill switch / emergency brake, though:
> For months, Tesla’s robotaxis in Austin and San Francisco have included safety monitors with access to a kill switch in case of emergency — a fallback that Waymo currently doesn’t need for its commercial robotaxi service. The safety monitor sits in the passenger seat in Austin and in the driver seat in San Francisco
Waymo absolutely has a remote kill switch and remote human monitors. If anything Tesla is being the responsible party here by having a real human in the car.
Fun post. I'd be interested to know: How many consecutive Truth Booths (or: how many consecutive Match Ups) are needed to narrow down the 10! possibilities to a single one?
Discussing "events" (ie, Truth Booth or Match Up) together muddles the analysis a bit.
I agree with Medea above that a Truth Booth should give at most 1 bit of information.
Based on my research, MUs perform better than TBs. For my simulated information theories, the MUs gained ~2 bits of information on average vs ~1.1 for TBs.
So if only MUs, we're talking around 10 events - meaning you could get enough information on MUs alone to win the game! Conversely, it would take about 20 events to do this just for TBs.
It's not super obvious from the graphs, but you can just about notice that the purple dots drop a bit lower than the pink ones!
So, for 10 pairs, 45 guesses (9 + 8 + 7 + 6 + 5 + 4 + 3 + 2 + 1) in the worst case, and roughly half that on average?
It's interesting how close 22.5 is to the 21.8 bits of entropy for 10!, and that has me wondering how often you would win if you followed this strategy with 18 truth booths followed by one match up (to maintain the same total number of queries).
Simulation suggests about 24% chance of winning with that strategy, with 100k samples. (I simplified each run to "shuffle [0..n), find index of 0".)
Agreed. There's an argument elsewhere about how a truth booth can possibly have an expected return of more than 1 bit of information, but in reality most of the time it's going to give you way less than that.
{kind=link}
{kind=link}
reply