"When taking the geometric mean of the benchmarks for this article today, The Threadripper 3990X came out overall 26% faster than the dual Xeon Platinum 8280, which is a very nice accomplishment since such a configuration currently retails for $20,000 USD worth of processors alone."
See https://stackoverflow.com/questions/38029698/why-do-we-use-c... from a few years ago. The gist is CPUs are more versatile in the work they can do, support larger scenes, and the render doesn't have to be in real-time so it's not a make-or-break comparison as video games would be.
I'm not thinking on the specialized GPU parts for shading and mapping, but pure floating point hardware. With 3D you are doing lots and lots of floating point ops that should map easily to what GPUs do best.
OTOH, GPUs are still harder to program than CPUs and I can only imagine what the SFX crew would hear when they have to explain the movie can't be released in summer because the GPUs are too hard to write software for.
As Linux becomes more competitive with Windows from a user experience point of view, I wonder if superior support for these new crazy AMD processors might help give it a boost. I'm sure many graphics people would move (if only Linux had good support for applications like Photoshop).
I'm curious what performance would be like on a linux hosting a 128 thread windows VM. I expect it to be worse than running windows on the bare metal, but maybe not. I could see a series of deficiencies in windows being eliminated with the linux host -> windows client topology.
I assume that the issue with processor groups on windows is that something somewhere is hardcoded to represent some kind of per-CPU state as bits in machine word. Having some kind of hypervisor as an additional layer will not help with that.
I have the 3970X and use it with Ubuntu. It's fun to have a lot of cores, but in the beginning it's highlighted some areas where open-source programs aren't assuming you're going to use that many cores (similar to what they talk about for Windows). So you see OOM errors with make, see program crashes from defaults being too low (such as creating too many Postgres connections), things like that.
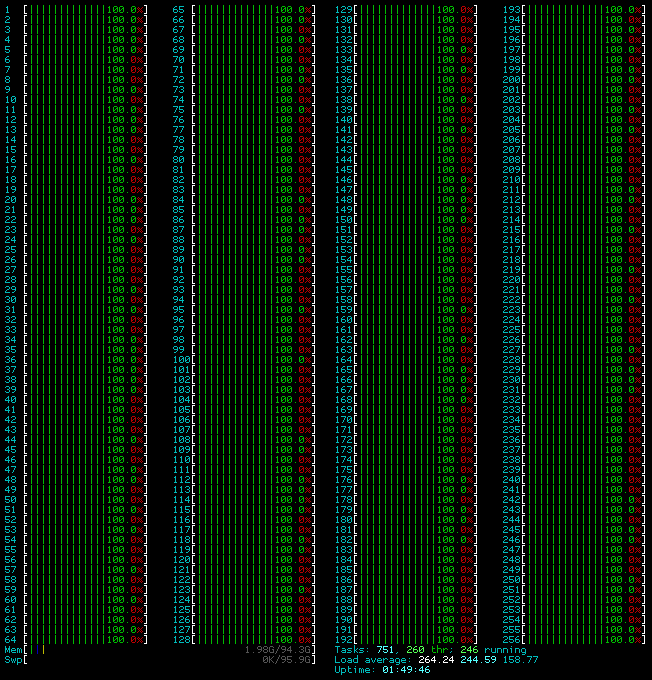
Not taking away from those developers, just sharing my experience. When you do get something that works really well (the newest version of Julia makes it easy to write multithreaded code), it's hilarious running htop and seeing 64 threads of green running.
I've got a 256 thread machine under my desk at the moment, I find myself frequently disabling threads because i'm out of memory.
I don't think people fully grasp that lots of applications memory requirements scale with the number of threads. Just running gcc against C make files can burn 1/2 a GB a process, multiply that by the 8 cores most people have and 16G of ram leaves plenty of memory for Firefox/etc.
OTOH, 128GB of ram in a 256 thread machine, is borderline out of ram. Build a project where its more like 2G of ram per process (looking at a lot of recent big public google projects) and its more like I need 1/2 a TB and a bunch of swap to keep the project from OOMing.
So at this point I might use that as a general rule, 2G per thread. So your looking at another ~$1.5k+ or so in RAM for this machine for most purposes.
I second this. My experience with many core machines (32-64 cores) is kinda dissappointing so far.
Yes, running "make -j" on these machines feel amazing at first, but you will soon either 1) run out of memory, or 2) notice that you don't need so many cores anyway due to build dependencies.
Hmm, my experience has been resolutely great; we just upgraded to 64 thread 3970x's with 256GB of RAM, and pretty much everything worked smoothly out of the box; I'm very pleasantly surprised by the lack of tuning necessary.
We did do the math and decided that for us 4GB per thread is likely safe up front; 2GB per thread might have been pushing it. Another reason to avoid the 3990x (for us) was the tricky scaling of the previous generation's 2990WX; We don't have faith that all of our code would run well on the more memory-channel constrained machine.
I mean, if you're just running a single fairly small build, sure, it's likely overkill...
It sure is fun to see the entire top half of htop being taken up by individual CPU bars, but this is another program whose assumptions have been overtaken by the current silicon: At some point it is not that helpful anymore and makes looking at the processes themselves harder.
Sadly the development of htop seems to have stalled, patches/PRs for that and many other issues remain unmerged and unanswered.
> It sure is fun to see the entire top half of htop being taken up by individual CPU bars,
You should have seen it with the Xeon Phi - the Phi could do 4 threads per core and the big ones had 72 of them, for a mind-blowing 288 threads. It was, however, much less forgiving than either of these beasts - L2 cache was Atom-sized and cache misses were not cheap.
IIRC, the SGI Origin 2800 could go up to 512 MIPS R14000 processors. It's one thread per socket but, with 512 sockets and a single memory image, it'd most likely end up crashing htop. ;-)
Yes, that was generally my point. Even if available code already took advantage of multiple cores, my experience has shown that currently these chips bring out some latent assumptions on what hardware the code will be running on (whether that's OOM or UX or whatever)
While most of us nerds may be geeking out at the 64 Core CPU all running 3.4Ghz+ priced at $4K and beating the Intel $20K counterpart [0], The reality is that the market for these seems to be very small. If we look at recent AMD [1] and Intel [2] results, it is clear AMD isn't gaining much. 70% of the PC market are Laptops, and majority of the 30% Desktop market are Business uses which generally prefer Intel. The Server market is extremely slow because of long term contract and other reason.
I just wish they could better market themselves to CIO / CTO / CEO rather than prosumer, enthusiast market.
Or they could try and convince Apple to use it on Mac, I am very certain the rest will follow.
Mobile growth was huge, and this was even with the older 12nm chips, and at best, mid-tier laptop models. This year I suspect will be even better as the 7nm 4000 series beats the Intel competition across the board, and as OEMs seem to be finally putting the AMD chips in higher-end models.
HP, Dell, Lenovo, Apple, ASUS, just these 5 vendor alone represent 70%+ of the market. And if you start adding smaller ( Comparatively Speaking in unit shipment ) brands Such as Samsung, Microsoft, Sony, Acer, Toshiba, you are now edging close to 90% of the Market.
Those top 5 vendors has long term relationship with Intel. So their AMD offering seems to be very lacking or purely as a play to have more bargaining power with Intel. Not to mention Intel's consumer marketing is far better than AMD.
Unless consumer ( not us, but average consumer ) reacts favourably, I dont think it will make much of a difference in terms of volume and unit shipment. It might do well in Gaming Laptop, but it seems most gamers prefer Nvidia.
AnandTech mentions 512GB RAM limit for 3990X - that would mean there are 64GB ECC UDIMM modules somewhere? All I could find were rare 32GB UDIMM modules at best, capping RAM to 256GB instead...
I'm waiting to see if/when EPYC Milan are released for price cuts to Rome. I already have an SP3 board and dual-CPU + VRM watercooling block. Some other bits on order are delayed because of Coronavirus, which is fine because I'd rather people be safe than fill orders for material stuff.
Say you created 32 dual vcore VMs with this, each with 2GB of RAM. How would they perform simultaneously together, vs a separate dual core PC (like a core2duo)? I don't know very much about the performance differences or if its even possible to compare such a thing.
Probably not near as well, if they're all actually doing anything. You'd hit bottlenecks moving data around, the bus used to fetch memory isn't 32 times as wide, and the memory isn't 32 times as fast, same with other resources.
You could in practice run quite a few VMs before you'd run into trouble, especially if most of them are idle at any given point.
That's some data I'd love to see.
32 1u servers all connected with fiber or 10gig vs 32 VMs on the same host vs 32 k8s pods on the same node. I'm wondering if the same test would scale from 4 hosts/VMs/pods
I don't even think there's a benchmark out there for such a test.
It's still much faster than any Core 2. It's faster than 2 cores of Sandy Bridge on my older 2950x, so I'd expect 39z0x to be even faster, probably beating older Skylake.
Yeah, I'm sure it's going to depend a lot on workload. If each one is in some crazy tight loop, CPU bound without using much working set of memory at all, it should be faster.
Or more realistically if they're usual VMs and idle the vast majority of the time, that should be faster too.
VMs in general are more memory-bound than CPU-bound (exceptions for things like SQL servers, encoders, etc). Hypervisors are generally pretty good about spreading VMs across a pool of CPUs and grabbing whichever is idle at the time. You can manually set affinities to always use specific cores, but it's generally wasteful to do so.
One caveat (at least with how vSphere 5.x worked) is the hypervisor has to claim all CPUs at the same time in order to do work, even if the other guest CPUs are idle. For example, if I have a 4 core VM on a 6 core host, it has to wait for 4 of the 6 to be free before the VM gets to do anything. So sometimes VMs with less CPUs can outperform one with more for the same workload. Getting proper measurements on your loads (peak/avg CPU, memory, disk IOPS etc) is critical to a good migration.
What he did was he took a single 32 core AMD CPU to replace all the computers in his house, including gaming PCs. At around 00:54, he mentions that the cores on the CPU are not "weak cores".
The VMs, in addition to dealing with the normal VM overhead we all already understand, would have much lower (like an order of magnitude) bandwidth to main memory and a similarly smaller share of L3 cache, in both cases because the resources are shared across all 32 devices.
So the answer to the question depends heavily on how cache-resident the problem you are throwing at them is. They'd do great mining bitcoin and be a total disaster as memcached hosts. More typical workloads will be somewhere in the middle.
Depends on target dual core machine spec. If all VMs run in full or heavy tasks you might face issues with scheduler. But I believe with lot of tunning on host like using numa, cpu passthrough, pinning and using light guests you might get close to those numbers with reasonable workload
I've not gotten my hands on a TR3. But rome gives you the option of 1, 2 or 3 Nodes Per Socket. Various benchmarks (eg, stream) published by vendors such as Dell show better performance in 4NPS mode. My own testing on Netflix workloads shows a similar speedup.
I run my dekstop (2990WX) in numa mode, exposing the real topology to the scheduler, and I find that it seems to help compilation times.
> I feel an intense desire to learn high performance computing to take advantage of this thing.
Learning high performance computing will let you take advantage of other things too. Like, for example, current desktop workstation processors with "just" four cores.
On the other hand, writing and debugging a program that uses 4 of 4 cores will help you feel confident enough to write and debug a program that can use 32 of 32.
Elixir, erlang, julia make using the smp of your system easy and natural. Go (you have to set up a bunch of things like channels and maybe worry about cleaning them up) and Java if you don't mind a bit of struggle.
If you want low level you can use c, c++ which are both dangerous, rust, zig (I just did some multithreaded stuff in zig and it's fantastically easy).
1) A bit about what I'm doing with zig. I am working on an FFI interface between elixir and zig, with the intent to let you write zig code inline in elixir and have it work correctly (it does). https://github.com/ityonemo/zigler/. Arguably with zigler it's currently easier to FFI a C library than it is with C (I'm planning on making it even more easy; see example in readme).
2) The specific not-in-master-branch feature I'm working on now is running your zig code in a branched-off thread. Fun fact about the erlang VM: if you run native code it can cause the scheduler to get out of whack if the code runs too long. You can run it in a "dirty FFI" but your system restricts how many of these you can run at any given time. A better choice is to spawn a new OS thread, but that requires a lot of boilerplate to do and it's probably easy to get wrong. Making it also be a comprehensive part of erlang's monitoring and resource safety system is also challenging, and so there's a lot to do to keep it in line with Zigler's philosophy of making correctness simple.
3) Zig does have its own, opinionated way of doing concurrency. I honestly find it to be a bit confusing, but it's new (as of 6 months) and is not well documented. I believe the design constraints of this are guided by "not having red/blue functions", "being able to write concurrent library code that is safe to run on nonthreaded/nonthreadable systems"
4) The native zig way of doing concurrency is incompatible with exporting to a C ABI (without a shim layer) so I prefer not to use it anyways.
5) Zig ships with std.thread. I believe it's in the stdlib and not the language because some systems will not support threading. But since I'm writing something that is intended to bind into the erlang VM (BEAM), it's probably on a system that supports threading. Also I believe that std.thread will seamlessly pick either pthreads or not-pthreads based on the build target, which makes cross-compiling easy.
6) So yes, figuring this all out is not easy (zig is young, docs are not mature), but once you figure out what you're supposed to do, the actual code itself is a breeze, this is the code that I use to pack information to connect the beam to linux thread and launch it: https://github.com/ityonemo/zigler/blob/async/lib/zigler/lon.... I really hope the docs come with guides that will make this easy in the near future.
I'm relearning c++ right now just because I am building a poker solver for a toy project.
You are right btw, if 32 core cpus become common because of a race to the bottom in prices I imagine there will be a massive increase in demand for programmers with the experience to program massively parallel systems.
I'm enjoying the Rust ecosystem. Everyone writes programs with multi-threading in mind, because the language requires everything to be thread-safe anyway.
It only requires thread-safety for stuff that's actually being shared across threads. Which is even more important since it means you're not paying for thread safety via reduced performance where it isn't needed.
Yep, and with the ease of concurrency in Go and Rust, it'll be freakin' awesome. And hopefully, we'll get some novel security research in areas dealing with attacks against concurrency and parallel execution.
...but without a sentence or three about the reasons you think Rust is more suited for parallel workloads you are just giving Rust users a bad name again (see Rust Evangelism Strikeforce).
That's completely fair, and rather than take on why it handles parallel cycles better during workload better, I tend to take a different approach with Rust and parallelism. I enjoy the compiler and parallel work loads and the elimination (well, reduction, let's face facts) of safety concerns and data races. It isn't that these same things can't be done, and done as well, with other languages but the built in tool chain is done without extension with Rust. Now, there is a learning curve and a different programming paradigm (though not a radically different as I was warned), which I happen to enjoy. It won't be for everyone. No language is. The resources are there and free (online) and I do encourage people with some spare time to give it a spin, but I don't think it's the end of the world if people don't want to =)
That being said, I like it, but I tend to use Python more. I wish I had more of a chance to use Rust in my daily life, but I don't use it at work =/
Python is just about the worst major programming language to write high-performance code in. The only slower major language is Ruby.
If you're using Python to invoke highly-optimised native-code, then your performance will be excellent (as shown by the various Python numerical libraries), but performance-sensitive code shouldn't run in the Python interpreter.
As others have said, Python also lacks true multithreading (its threads are capable of concurrency but not parallelism, on account of the GIL), but you do have the option of just running a bunch of Python processes in parallel. I imagine that's a workable solution at least some of the time, but I've never explored this, so I don't know how good the library support is.
Edit: Someone else mentioned 'mpi4py' which seems to be a Python library for multi-process work.
Or python with mpi4py. MPI is the perfect multiprocessing paradigm for parallel python code, since you avoid the GIL. You can easily use MPI on a single workstation, or scale it to run on a supercomputer.
Python with asyncio and multithreading doesn't take good advantage of multiple cores due to the global interpreter lock. With multiprocessing, one pays big costs in IPC.
Python is not at all suitable today for parallelism. Which is one reason why languages like Go and Elixir are gaining so much traction.
Subinterpreters share a common GIL. Also subinterpreters don't share Python objects, which means among other things that all modules are imported separately in each SI, which increases startup time, memory usage and reduce cache effectiveness.
It's a band-aid. If you want to run Python code in parallel, without large overhead, then CPython is simply not your environment to do so, and Python is not a good choice overall in that kind of endeavour.
Elixir uses slow interpreted vm, you can't put it into the same high performance category and golang, java, c++ and rust can't do well on massively multicore systems on their own, you would have to fight them to do it, ditch idiomatic ideas and effectively build your own runtime and use your own concurrency model (not shared memory multithreading!). So they are more like every other language that is somewhat close to the primitives that OS and hardware provide, not actually well suited for the job itself.
Elixir is compiled. And as someone who worked in HPC, I would really not call golang high performance (by the criteria which people in HPC consider "high performance")
It's not like they're intentionally broken, just have whatever bugs come with being the first revision. These are the units they send out to journalists and big companies to do benchmarks, test software for, plan large scale rollouts, etc. Having them work the same as the retail units is pretty essential for that purpose.
That said, one of my units has a clock speed that doesn't match any of the retail models (I guess they didn't end up selling that model?), and another doesn't seem to work with threading (or whatever AMD calls it) enabled. But that's a small price to pay for the money saved.
The 8 memory channels of the EPYC against the 4 of the Threadripper that the article mentions is not just about how much memory you can install, but memory bandwidth. An L3 cache miss should be roughly twice as expensive on the desktop platform than on the server one.
Except that in the 90's you didn't have hardware from 15 years prior that was still generally usable for baseline tasks. Nobody was running Linux on their old ZX Spectrums or Commodore PET's! In fact, running an up-to-date Linux with mainstream features (GUI) was only for relatively high-class hardware.
Unfortunately, I'd be hesitant to call a whole lot of hardware from 15 years ago "generally usable for baseline tasks", either. Even running just a web browser, a 2005-era machine is gonna struggle quite a bit on modern websites with a modern browser and underlying OS.
Wow, we're getting close to the amount of cores/threads that Xeon Phis boasted, but with actual per-core performance. And on an (almost) mainstream platform!
{kind=link}
https://www.phoronix.com/scan.php?page=article&item=3990x-th...
"When taking the geometric mean of the benchmarks for this article today, The Threadripper 3990X came out overall 26% faster than the dual Xeon Platinum 8280, which is a very nice accomplishment since such a configuration currently retails for $20,000 USD worth of processors alone."