Wikidata is a fantastic data source for all sorts of applications, not just for the Wikimedia projects (infoboxes, templates, etc.). I'm also excited about the Wikifunctions project (https://en.wikipedia.org/wiki/Wikifunctions) to created a large body of executable snippets that can be applied to data types.
Its just me (Jama Poulsen) currently. I hope at some point to be able to work with more people on this project and also to have a base for other archives / institutions (as a B2B product and service) to use the "Conzept UI" for their knowledge base. The Conzept framework is already pretty generalized, multi-lingual and customizable, but more needs to be done. I'm aiming to be able to do a first pilot at the end of the year (or later, depending on the progress). Feel free to send me a message if someone is interested in this.
There will be better user documentation coming (the current guide is a bit dated). Still thinking how to make that more modular, UI-integratable and maintainable.
The whole main app design and UI is from scratch, but many embedded apps are developed by others (I've been donating to some of them for their great work, but more needs to be done here IMHO). No papers or anything on all that currently.
Thanks! I spend a lot of time tweaking the UX. Its not easy to build a fluid and fast experience (especially on mobile).
The user base is still small, which is fine, as there are still many small issues to fix. I'm having a lot of fun developing this and hearing the feedback of users.
I started the project mostly for myself, to have a more integrated topic exploration tool, but things grew to also be of use to others. I think the main use case is just learning about topics of personal interest. I would like to experiment with some social features in the future (eg. ephemeral audio chat for topics).
SPARQL over Wikidata is one of the closest things to magic on the Internet. It's incomplete, the runtime is slow, it dies on too much data, but it's amazing being able to think up random questions and actually ask them, however frivolous. Stuff like "who's the most successful footballer from my home town?" or "which part of India has produced the most test cricketers?" is really easy. Makes me wish I'd taken the quantified self more seriously because there's so much I'd love to find out with rich enough linked data.
You can download a data dump and run your own queries locally if the limitations of the online service are of concern. Full dumps of the whole Wikidata are easily available, or you can export a limited result set from the query service and run your own local queries on that data.
I found SPARQL pretty hard to deal with. Some time ago I wanted to make an overview of various election results to prove a certain point. The data is in there, I can see it in the UI, but I had a lot of trouble writing a script to retrieve it (so I could make a nice table and/or chart). Basically, after an hour I failed and gave up.
I will readily admit this is due to my own ignorance; I just wanted to post a point in a Reddit comment and investing a lot of time to properly learn SPARQL wasn't worth the effort, but I wish the data was more easily accessible without a fairly large time investment. WikiData is basically the only structured source for these election results that I could find (the government publishes them of course, but in a PDF that's always different).
And I'm a programmer by trade! Non-technical people will have an even harder time.
WikiData is pretty good, but I feel it could be truly fantastic if the data was more easily accessible.
I think a big reason that sparql is hard, is it looks like SQL but has a really different data model. People who know sql tend to apply sql intuitions to sparql, which leads to confusion. But once you get past the learning curve its really not that bad.
> once you get past the learning curve its really not that bad.
Kind of applies to everything, no? :-)
But yeah, I don't think GraphQL is "bad", it's just hard to get started with (same applies to SQL really, although we're all used to that so we've forgotten about getting started with it). I want to use WikiData maybe ... once a year? Or less? I will probably have forgotten a lot of stuff next time I want to use it.
You have to be familiar with Wikidata's underlying model and how the data you care about are mapped to it, but having done that it's just a matter of picking one of the many example queries and tweaking it so it references the right bits of data.
Yeah, happy to admit SPARQL itself is hard, and every query requires having five wikidata tabs and three stackoverflow ones open. But, I find myself battling through because the results are worth it.
I made a script to get the highest mountains in norway and get them on a map in Jupyter - looks nice, includes pictures if there are etc, but it doesn't pick out all the highest mountains. Most of them, but some are missing.
I will admit I rarely use it for things that are so mission critical that this would matter. That said, it's always nice to leave the data more complete than you found it in these cases.
Some of the comments suggest not everyone is aware of the history.
This is a Hacker News thread from March 2012 titled "Wikidata: The first new project from Wikimedia Foundation since 2006" that is interesting to revisit:
We are using in my company. We imported the whole database into a graph db and we are running queries/marking entities in order to enable things like contextual/semantic search. It is a pretty good database.
This is what enables you to search for things and not strings (as Google does).
I wish Google would just search for strings the 60% of the time it doesn't know the thing I'm looking for but really, firmly, and persistently thinks it does. Like it used to. It should get the hint and switch methods somewhere around or before the 10th page of useless, mostly identical results.
Unlike DBpedia, Wikidata is not structured content extracted by parsing Wikipedia articles, but instead a structured collection of factual knowledge created by human editors.
True, but then there are also quite a few bots editing the Wikipedias. In the end, bots are still run by humans, and are subject to prior community approval.
This is different though. This is from wikipedia, and aims at structuring data that is used in wikipedia. I am guessing this is because if something changes in the world, then in wikipedia, the information needs to be changed in all articles (all languages, all connex articles etc.). This would add a level of indirection for facts.
DBPedia board has been faffing about regarding the new hyper-relational data model [0] and has come up with a bunch of hack-ish solutions (read: esoteric data models) to incorporate it. As far as I remember, there were dumps from 2018 with some hyper-relational facts but by and large the go-to dumps is from 2016-10 [1].
I think they acknowledge that info-box information is no longer good enough (both in coverage and completeness) and have handed over the moniker of the open-access KG to Wikidata. To their credit, I think its the right call.
src: I worked in a lab lead by DBPedia's founder (and one of the contributors to the original infobox to KB code).
^^This enables, amongst other things, fact's validity to be quantified. Instead of saying <barack obama> <president> <united states>, you can now say {<barack obama> <president> <united states>} <from> <DD-MM-YYYY>; <to> <DD-MM-YYYY>
Wiki data is awesome. I’ve been considering using it for some projects, but the main thing that’s keeping me away is the concern that some moderator will decide that my data doesn’t fit and remove it. Can anyone speak to this concern? On WP for example notability is a big thing, how does this work in Wikidata?
All data is notable on Wikidata as long as it can be directly sourced, and/or structurally linked to some other data that's itself notable. There's nothing like the concern for the "encyclopedic" that one might find on Wikipedia. The most obvious example of this is the zillions of entries for individual scholarly articles, which are included because these can be endowed with machine-readable info about authors, publishers and citations that is of general interest.
Please read it carefully before creating new items. If the item you want to create is about yourself, your new business or the song you just wrote, it likely does not meet the notability policy.
> I’ve been considering using it for some projects, but the main thing that’s keeping me away is the concern that some moderator will decide that my data doesn’t fit and remove it.
To me the greatest value of Wikidata was making me aware of RDF and SPARQL.
In most cases, if you are relying on data business needs, it would be best to maintain your own RDF dataset and host it either just on HTTP, or on something like https://dydra.com/.
WikiData deseperately needs RDF ingestion, and if this is made available (can be done outside of Wikidata) then it would be easier to periodically sync datasets with Wikidata.
On that note however, you could export all Wikidata triples you need and just host that on your own SPARQL server (e.g. Jena) or use it with RDF tools like rdflib.
RDF ingestion is problematic for Wikidata, because importing a dataset to Wikidata requires reconciling existing entities so as to avoid duplicare entries. The easiest way to achieve that is to publish your dataset online, create a linking Wikidata property for it, then ask for it to be imported in https://mix-n-match.toolforge.org where reconciliation can be done by the crowd.
Last I checked mix-n-match was using CSV, while this is okay, it still would be nicer to have direct RDF ingestion. And yes, I realize the reason why Wikidata does not have it, but it is not impossible to provide, just really difficult. I would work on it if I had more time and would likely sometime in the future.
I made a data import project for Brazilian higher education organizations and was impressed by the amount of documentation, process and tooling available. On the other hand, I was also impressed at how few data imports are completed for me to take as example. To this day I receive dozens of notifications about edits on the entities I created so I’m happy to see it’s alive and well.
One of the big added value of Wikidata imho is that each Wikidata page mention the identifiers for the same item in several other datasets (OSM, wikipedia, geonames, etc).
Given the fact that SPARQL allows cross-DB queries, Wikipedia becomes an interesting federation dataset.
It seems like magic, but it is possible to entirely outsource the infobox to wikidata. See for example https://fr.wikipedia.org/wiki/Mart%C3%ADn_Abadi whose infobox is created with the sole `{{Infobox Biographie2}}` line.
It appears that Wikidata semantic network statements are untyped and binary rather than n-ary. Ugh. Amazingly, the above URL has a picture which shows exactly why this is such a stupid approach. The location of San Francisco(Q62) is a "Geolocation" consisting of a latitude and a longitude. That is, the statement is (if I'm reading this right):
location(San Francisco (Q62), Geolocation{-122.4183, 37.775})
This requires that Geolocation be a special type like integer or float. VERY BAD. There would be a massive proliferation of such things.
Alternatively Wikidata could do this as
Q95 (or whatever) = new object
longitude(Q95, -122.4183)
latitude(Q95, 37.775)
location(San Francisco (Q62), Q95)
This is the standard reified approach used by binary semantic networks and is ugly as sin, unnecessarily polluting the object space with little object poops. The clean way to do this would have been to declare location to be ternary, so we could say:
Wikidata statements are not binary, and values are not untyped. However, there is the concept of “simple statements”, especially in conjunction with the RDF exports (although not untyped, these data usually look like binary relations). Indeed, any statement can be annotated by a list of “qualifiers”, each of which can have zero or more values, can have references (which can have their own qualifiers)
As for types, “GlobeCoordinateValues”[0], i.e., locations, form one of the types allowed for values, and consist not only of two integers, but indeed of four distinct values: latitude, longitude, precision, and the reference globe, since Wikidata does not limit coordinates to the Earth. There is also no “massive proliferation”, the data model[1] knows 12 types[2], of which four are four different kinds of texts (untranslated, monolingual, multi-lingual, and list of multilingual texts).
- "Borane" has two unlinked entries: Q127611 is "any chemical compound composed of boron and hydrogen atoms only" while Q15634214 is specifically boron trihydride. Both correct, but the latter should be labelled as an instance of the former.
- "Anomalocaris" has Q37395 for the "extinct genus of radiodon" (instance of "fossil taxon") but species (e.g. Q49557506 Anomalocaris cranbrookensis) do not link to it.
- There are no lists of links, for example Q936518 ("aerospace manufacturer") doesn't have a list of its instances (e.g. Boeing, Q66, or Arado Flugzeugwerke, Q624899).
> There are no lists of links, for example Q936518 ("aerospace manufacturer") doesn't have a list of its instances (e.g. Boeing, Q66, or Arado Flugzeugwerke, Q624899)
This is intentional, you can construct these via the query service. There's also an optional "gadget" registered users can add to their configuration, that can do this automatically when visiting a page for every instance of some "inverse" property.
Well, "what links here" gives you a general list of related pages without telling you which is relevant to the property you care about. It's sometimes useful (esp. for items with few incoming links), but the query service is a more complete solution.
Alas infoboxes on Wikipedia often have more info. Particularly, in the case of cultural phenomena people are frequently eager to populate the infoboxes.
Perhaps some kind of synchronization would be feasible, where with standardized infoboxes relations between known items could be extracted when specified on Wikipedia, and plopped into Wikidata.
For myself, I looked around for a service that could present infobox-data from pages in a category as a table, with filters and sorting. But ended up just firing API requests and parsing the boxes.
My favourite example is linking the street names from OpenStreetMap with the gender of the persons name from Wikidata ID to produce visualisations of the gender distribution of street names in (European) cities: https://equalstreetnames.eu
Normally when you hunt for information that you can't absolutely find an already-made API of you scrape the web and deal with regular expressions but this is definitely the easier option, using SPARQL. I can see a lot of potential information harvesting use cases for it.
There is a SPARQL query page, with useful examples included.
In general, Wikidata is not made up of discrete "datasets". Rather, each identifiable real-world entity, event or concept has a unique Q-identifier and a listing of "properties" that apply to that entity. So, to construct a dataset, you'd query for entities that participate in some set of properties you might care about.
Wikidata is a great resource, but the SPARQL query language seems more annoyingly complicated and confusing than it could be.
I'm using Wikidata to automatically categorize visited websites and used programs for time tracking purposes.
For example, here's a query to get the entity (e.g. company) that has a specific domain (news.ycombinator.com), and get the categories that entity is in that that are a descendent of the "service on internet" category:
Relations have to be written as `wdt:P279` even though they have names [1], and the query engine just silently accepts lots of stuff it shouldn't.
For example if above you do `"url"` instead of `<url>`, it will just not return any results because URLs is a separate type and URLs never match strings. And if an entity doesn't exist it will also just not return anything.
Then there's this hacky "label service" thing that implicitly creates new output variables (outer_categoryLabel) to make it actually return text.
The UX of the query site [2] is also pretty bad.
I feel like Wikidata would be much more used if it had a easier query language. Or better, real bindings to common languages with full intellisense for properties etc). Something like this:
In the old days, I had made a UI for SPARQL. Even adapted it to Wikidata.
But in the end, so few people cared about it that I abandonned it. (it still works fine, anyway).
{kind=link}
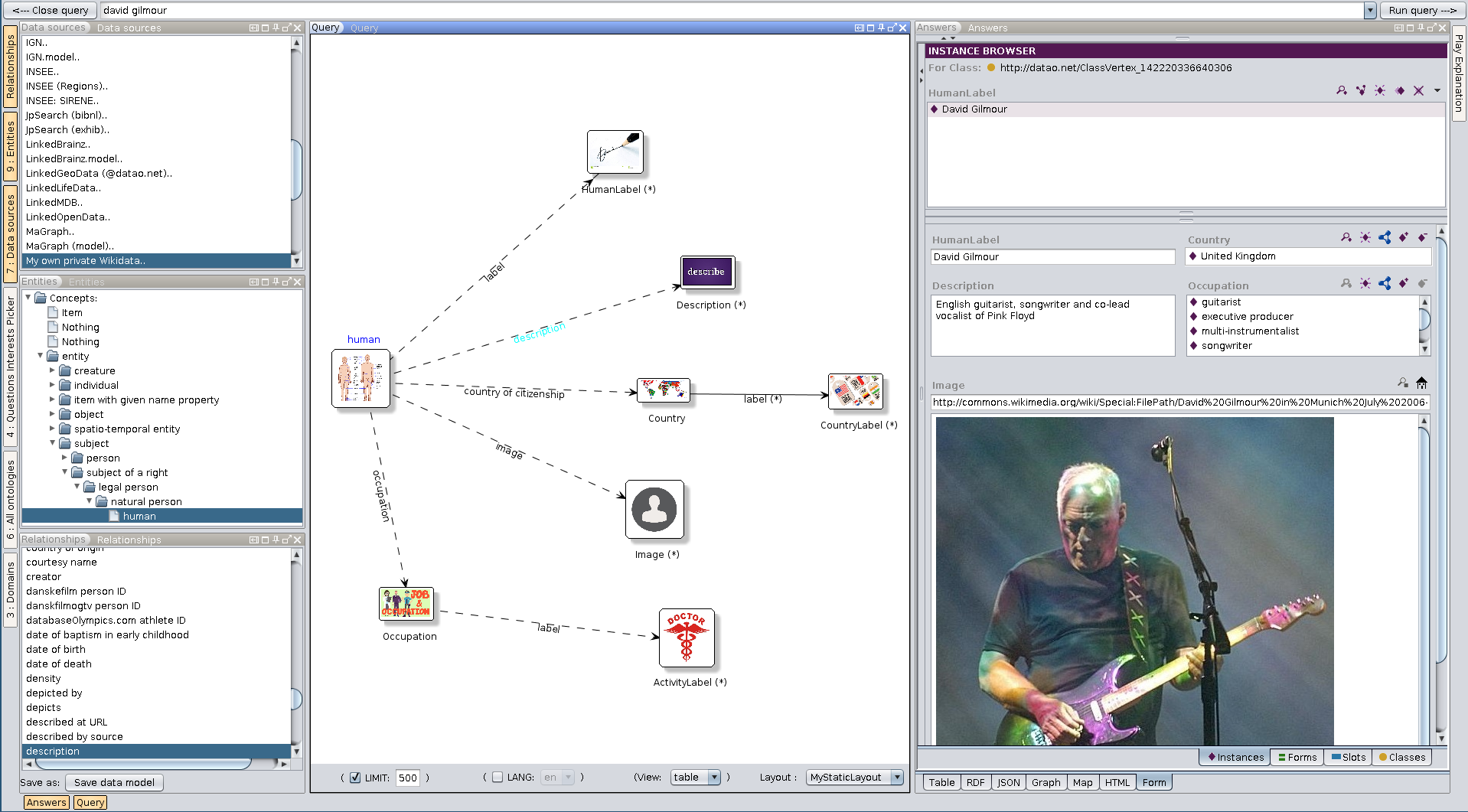
Wikidata is one of the main data sources in my Conzept encyclopedia project: https://conze.pt (https://twitter.com/conzept__)