You can ask your website: "What is the computational complexity of self-attention with respect to input sequence length?"
It'll answer something along the lines of self-attention being O(n^2) (where n is the sequence length) because you have to compute an attention matrix of size n^2.
There are other attention mechanisms with better computational complexity, but they usually result in worse large language models. To answer jart: We'll have to wait until someone finds a good linear attention mechanism and then wait some more until someone trains a huge model with it (not Groq, they only do inference).
Changing the way transformer models works is orthogonal to gaining good performance on Mistral. Groq did great work reducing the latency considerably of generating tokens during inference. But I wouldn't be surprised if they etched the A matrix weights in some kind of fast ROM, used expensive SRAM for the the skinny B matrix, and sent everything else that didn't fit to good old fashioned hardware. That's great for generating text, but prompt processing is where the power is in AI. In order to process prompts fast, you need to multiply weights against 2-dimensional matrices. There is significant inequality in software implementations alone in terms of how quickly they're able to do this, irrespective of hardware. That's why things like BLAS libraries exist. So it'd be super interesting to hear about how a company like Groq that leverages both software and hardware specifically for inference is focusing on tackling its most important aspect.
One GrogCard has 230 MB SRAM, which is enough for every single weight matrix of Mixtral-8x7B. Code to check:
import urllib.request, json, math
for i in range(1, 20):
url = f"https://huggingface.co/mistralai/Mixtral-8x7B-v0.1/resolve/main/model-{i:05d}-of-00019.safetensors?download=true"
with urllib.request.urlopen(url) as r:
header_size = int.from_bytes(r.read(8), byteorder="little")
header = json.loads(r.read(header_size).decode("utf-8"))
for name, value in header.items():
if name.endswith(".weight"):
shape = value["shape"]
mb = math.prod(shape) * 2e-6
print(mb, "MB for", shape, name)
tome's other comment mentions that they use 568 GroqChips in total, which should be enough to fit even Llama2-70B completely in SRAM. I did not do any math for the KV cache, but it probably fits in there as well. Their hardware can do matrix-matrix multiplications, so there should not be any issues with BLAS. I don't see why they'd need other hardware.
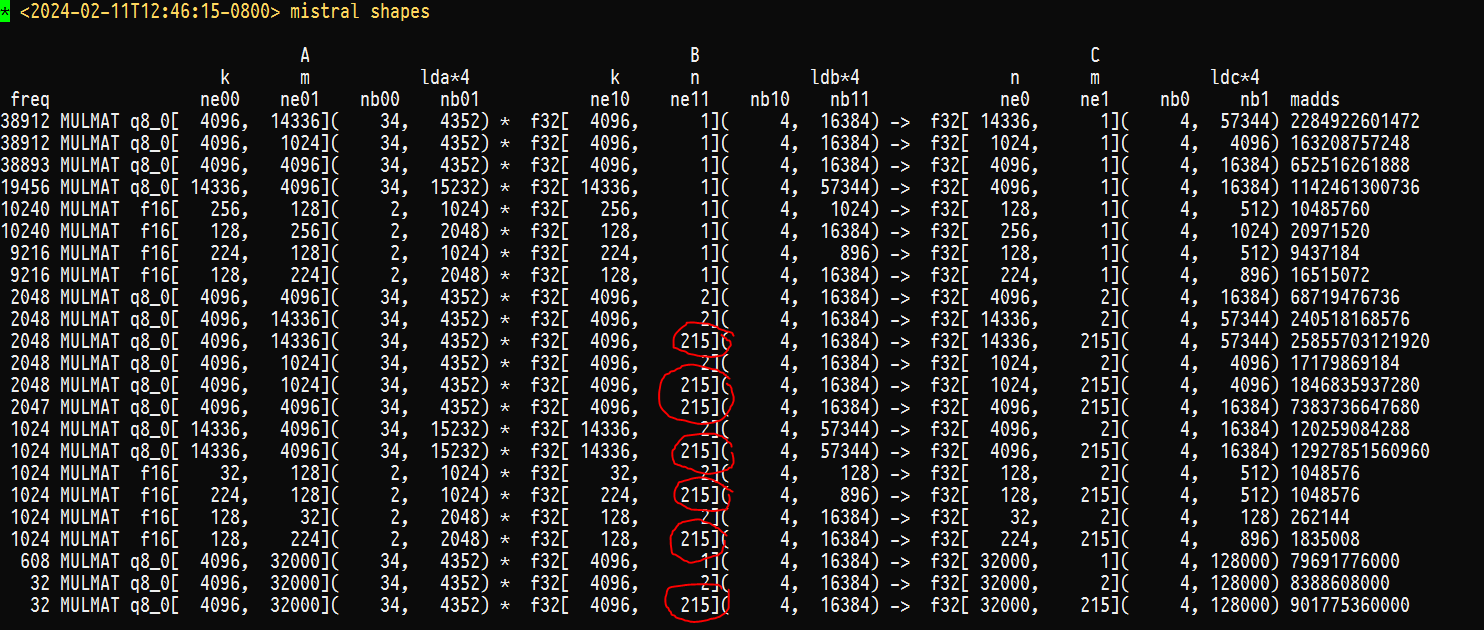
all I know is that when I run llama.cpp a lot of the matrices that get multiplied have their shapes defined by how many tokens are in my prompt. https://justine.lol/tmp/shapes.png Notice how the B matrix is always skinny for generating tokens. But for batch processing of the initial prompt, it's fat. It's not very hard to multiply a skinny matrix but once it's fat it gets harder. Handling the initial batch processing of the prompt appears to be what your service goes slow at.
{kind=link}